딥러닝은 인공 신경망을 기초로 하고 있다.
인공 신경망이라고 불리는 ANN은 사람의 신경망 원리와 구조를 모방하여 만든 기계학습 알고리즘이다.
인간의 뇌에서 뉴런들이 어떤 신호나 자극을 받고 그 자극이 어떠한 Threshold값을 넘어서면 결과신호를 전달하는 과정
에서 착안 한 것이다. 여기서 들어오는 자극이나 신호를 input으로 하고 Threshold값은 weight, 결과를 내는것이
Output 이다. 그림을 통해 관찰해보자.
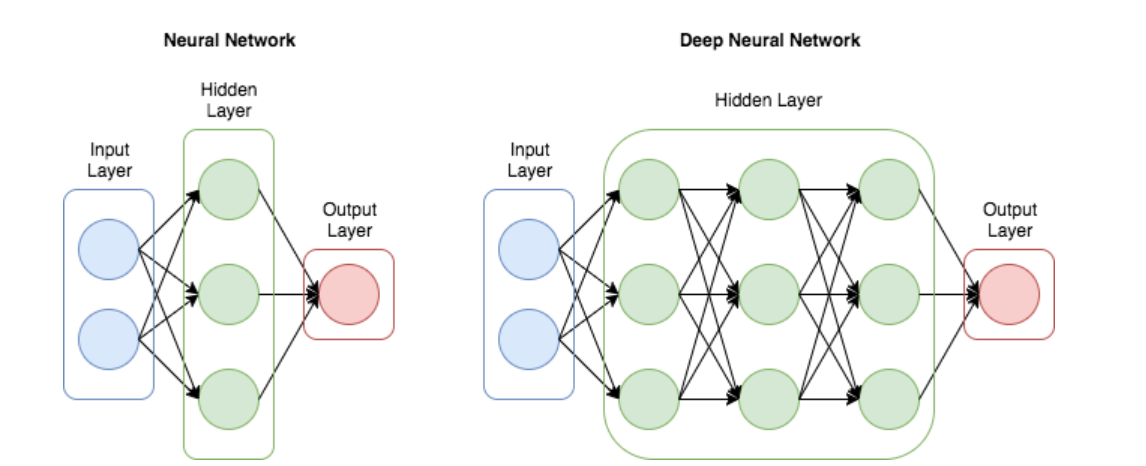
왼쪽의 그림이 ANN이고 오른쪽의 그림(2개 이상의 은닉층)이 DNN이라고 보면 될 것 같다.
이 두개의 모델은 weight를 가지는 선형 모델이라고 생각하면 된다.
무슨 얘기냐면, 왼쪽의 그림처럼 2개의 인풋값을 x[0],x[1] 이라고 하면
y=w[0]x[0]+w[0]x[1]+w[1]x[0]+w[1]x[1]+w[2]x[0]+w[2]x[1]+bias이런식으로 w라는 weight를 input에 가중해 주고
그 값들에 bias(상수값)를 더해서 Output을 예측한다. 이 때 우리가 해야 할 일은 x라는 input에 곱해질 w(가중치)
의 집합이 어떤 값으로 이루어질지 gradient의 역의 방향으로 가중치를 계속 이동시키면서 손실값이 최소화 될
때까지 모델의 w값을 개선시킨다.
ANN은 은닉층이 한 개밖에 존재하지 않기 때문에 최고수준으로 학습을 마친다고 해도 그 정확도가 매우 떨어진다
과거에는 은닉층이 늘어나게 되면 계산량이 증가하기 때문에 학습시간이 지나치게 느려져서 은닉층을 늘리기가
힘들었고 또한 훈련데이터가 부족해서 학습된 데이터에만 모델이 유효하고 조금만 형태가 달라져도 감지하지 못하는
overfitting문제가 있었다. 하지만 GPU,CUDA같은 그래픽카드의 발전으로 여러 개의 은닉층 학습을 소화할 수 있게 되고
Bigdata기법을 통해 다량의 훈련 데이터를 확보할 수 있게 되면서 점점 ANN->DNN으로 신경망이 발전하게 되었다.
또한 DNN은 컴퓨터가 스스로 분류레이블(예를들면, 과일을 분류하는 작업을 할 때 바나나=0,사과=1,수박=2..이런식의)
을 만들어내고, 공간을 왜곡하고, 데이터를 구분짓는 과정을 반복하여 최적의 구번선을 도출해낸다.
그리고 Pre-training기법과 Back-propagation을 통해 현재 최적의 학습방법으로 사용되고 있다.
하지만, DNN은 이미지나 영상을 이용한 학습에는 그렇게 좋은 방법이라고 하기 힘들다.
왜냐하면 이미지와 영상은 굉장히 큰 데이터량을 갖기 때문이다.
고해상도로 가면 갈수록, 컬러를 세밀하게 표현하면 표현할수록 이미지의 크기는 굉장히 커지게 된다.
당장 캠코더로 찍은 영상만 보더라도 보통 프레임당 1080*1920*3의 이미지 크기를 가지는데 이는 무려 6백만개 정도의
크기를 가지게 된다. 특정 부분만 확대하고 색을 줄이거나 제거하고 하는 이미지 전처리를 진행해도 한계가 존재한다.
또한 DNN에서는 이미지를 1차원으로 바꿔서 학습을 해야 하기 때문에 이미지의 특징이 사라지기 때문에 전체 사진에서
특정 개체를 찾아내는게 더욱 힘들어진다. 이를 해결하기위해 등장한 신경망이 CNN이다.
-CNN(Convolutional Neural Network)
CNN(Convolutional Neural Network)기법은 일반 Neural Network에서 이미지나 영상과 같은 다차
원 데이터를 처리 할 때 발생하는 문제점들을 보완한 방법이다.이미지는 480*480 같은 형태로 표
현되므로 하나의 row로 표현되지 않는다.

만약 위와 같은 강아지 그림이 있다고 하면, 이 사진데이터를 한 줄로 표현하게 된다면

이렇게 특정 픽셀들간의 연간 관계가 제거되면서 데이터가 큰 손실을 입게 된다.
그러므로, 이러한 연간관계를 유지하면서 이미지를 변환하는 CNN방식이다. 아래 그림을 보자.
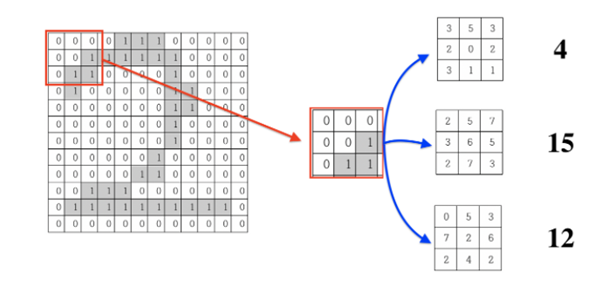
이 그림은 12*12 = 144개의 픽셀을 가지는 그림이다. CNN에서는 임의의 값을 가지는 n*n크기
의 필터를 위 그림과 같이 원본 이미지에 컨볼루션 연산을 하면서 원본의 데이터를 압축시킨다.
3*3필터를 사용하고 stride없이 진행한다면 위의 12*12 그림은 10*10 그림으로 압축 될 것이다.
비어있는 공간에는 0을 채워주는 pooling의 과정과 필터의 컨볼루션,이러한 과정을
계속 반복하면서 결국 최종적으로는 12*12의 그림이 1차원의 데이터로 변형되게 되는데 이를
Flatten과정이라고 한다. Flatten과정을 거치면 이후에는 그냥 DNN과 동일한 네트워크를 이용해서
Output을 출력하면 된다.
CNN도 이미지를 컨볼루션과 풀링을 통해 축소시키는 과정에서 꽤 많은 시간이 걸리게 된다.
이를 해결하기위해 R-CNN,fast R-CNN, YOLO등 다양한 개선된 형태의 연구가 이루어지고 있다.
'딥러닝,CNN,pytorch' 카테고리의 다른 글
| [딥러닝] 1개층을 가진 뉴럴 네트워크 경사하강법(backpropagation, backward 계산) , 역전파 (0) | 2021.05.30 |
|---|---|
| 딥러닝 활성화함수(Relu , Maxpool2d) (0) | 2021.05.30 |
| 파이썬 pytorch를 이용해서 CNN을 코딩으로 구현해보자. (0) | 2021.05.10 |
| 파이썬, 딥러닝 손실함수 교차엔트로피손실(CEE) 개념정리 (0) | 2021.04.21 |



