이전의 포스트에서 CNN의 개념에 대해서 설명했다.
그렇다면 코딩을 참고하면서 pytorch기반의 CNN이 어떻게 구현되는지 알아보자.
(Tenserflow의 방식도 거의 비슷하다.)
일단, CNN으로 형성된 모델을 한번 살펴보자.
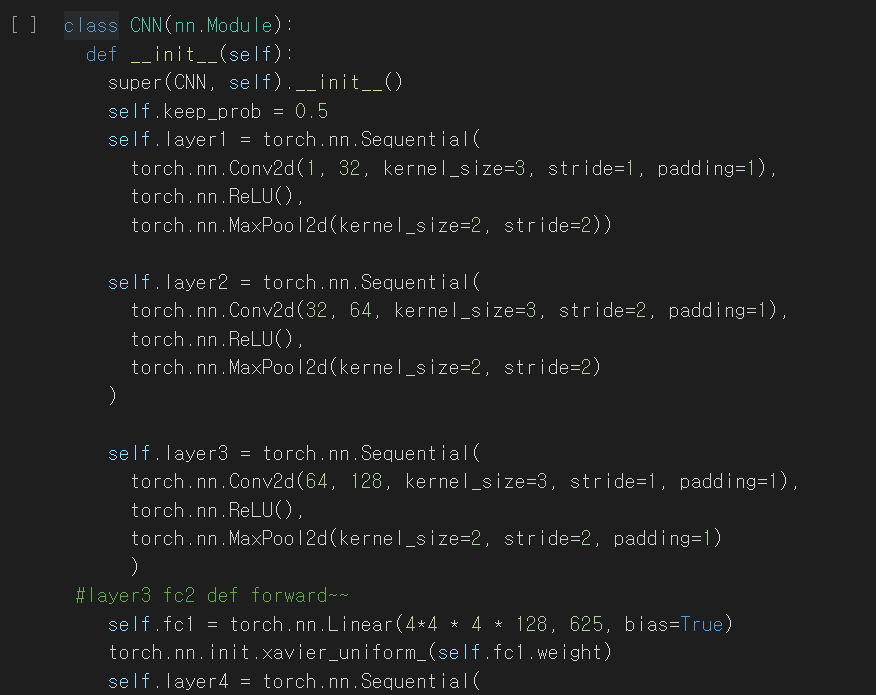
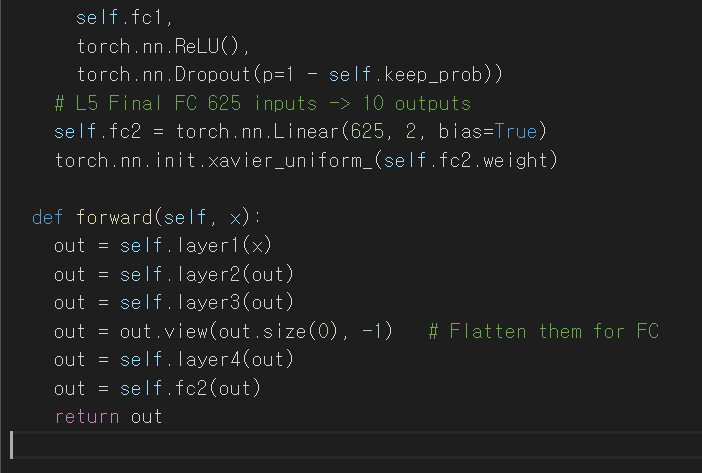
모델의 전체적인 모양은 이렇게 생겼다.
세부적으로 뜯어서 보자면,
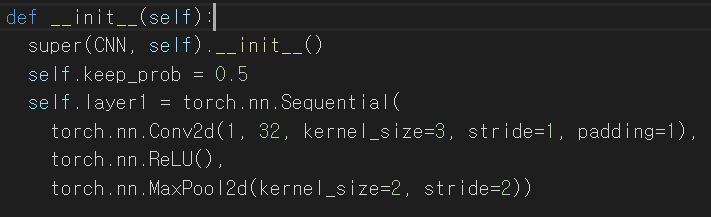
keep_prob은 CNN모델의 dropout에 사용하고자 선언 한 것인데 이는 나중에 다시 포스팅 할 예정이니 무시해도 좋다.
또한 ReLU는 gradient vanish현상을 막아주는 용도이고 MaxPool2d은 output size를 줄이기 위해 사용했다.
이 것들(ReLU,MaxPool,DropOut)의 자세한 설명은 나중에 따로 포스팅하고 지금은 CNN모델만 집중해서 살펴보자.
이 모델은 layer가 총 5개 존재한다. 지금 보고있는 것은 그중 1번째 layer이고 선형의 parameter를 가지는 Sequential모
델이다. 흑백의 이미지(1차원)을 input으로 넣을 예정이므로 1번째 층의 input channel은 1(흑백이니까..)이 된다.
nn.conv2d(input채널수,output채널수,필터사이즈,stride(필터를움직이는크기),padding(제로패딩여부))로 인자를 이해하면
되겠다. 그러므로 1레이어는 흑백(1)채널의 인풋을 가지게 되고 내가 원하는 것은 1차원에 3*3크기의 필터를 1의stride
로 진행한 32개의 결과값, 즉 32차원의 output을 얻고자 이렇게 모델을 만들었다. 또한 가장자리의 정보를 잃지 않기
위해 가장자리쪽에 컨볼루션 연산을 할 때 값이 없는부분을 0으로 채워서 진행하기 위해 제로패딩여부를 1로 정했다.
똑같은 방법을 반복해서 처음에 1개였던 채널은 1->32->64->128->625개까지 증가했다가 최종적으로
625개의 차원을 2개의 값으로 축소시키는 layer5를 지남으로써 CNN분류가 완료되게 된다.
여기서, 625개의 차원의 이미지일텐데
이 이미지가 얼마만큼의 크기를 가진 이미지 들일까??
예를들어 200*200의 이미지가 들어간다면 conv2d를 지났을때 이미지의 크기는 여전히 200*200이다.
즉 200*200의 이미지가 output 채널만큼 존재하는거다.
그리고 Relu는 단순히음수값을 지우는 활성화 함수로써 output의 크기 자체는 변화시키지 않는다.
하지만 Maxpool은 따로 포스팅 하겠지만 이 output 사이즈를 1/4로 줄여버린다.(2의 커널사이즈,2의 stride)
어쨋든 layer들에 Maxpool이 존재하기 때문에 output의 size는 200*200으로 유지되지 않고
변한다는 것을 알 수 있다. CNN을 거친 output의 크기는 다음 표를 따른다.


layer1 , layer2 , layer3는 CNN층 이므로 행렬모양(행성분과 열성분이 존재하는)을 INPUT으로 사용할 수 있지만
layer4와 fc2(layer5)의 경우는 일반 선형 모델이므로(torch.nn.Linear) 1행만 존재 하도록 view작업을
거치고 input으로 넣어줘야 한다. 이게 무슨 말이냐면
저번 포스팅에서 이야기 했지만

위의 강아지 그림을 그대로 넣어서 input으로 활용하므로 공간정보가 유지되는게 CNN이라고 했다.
하지만, 이 그림을 Linear모델에서 사용 할 때는 아래의 그림처럼 1자로 펴서 input으로 쓰게 되므로 공간정보가 사라지
게 되는 모델이 Linear모델이라고 한다고 설명했다.
그런데, 지금은 이미 CNN계층을 거치면서 공간정보가 저장이 되었기 때문에 이렇게 Linear모델에 다시 넣어서 차원을
축소시켜 주는게 훨씬 빠르고 정확하게 분류가 되기 때문에
모델의 앞쪽 layer는 CNN을 사용하고 뒤쪽 부분은 Linear층을 사용해서 수백,수천차원의 정보를 축소시키는게 좋다
결국 최종적으로 나는 1차원의 흑백이미지(n*n)를 넣어서 이를 3*3크기의 필터 32개를 통해서 32차원의 정보로 만들고
이를 다시 32->64->128->625까지 늘렸다가 다시 2개층으로 축소시키는 작업을 통해
이 흑백이미지를 0또는 1, 2가지중 하나로 분류가 되도록 CNN기반 모델을 만든 것이라고 설명할 수 있겠다.
'딥러닝,CNN,pytorch' 카테고리의 다른 글
| [딥러닝] 1개층을 가진 뉴럴 네트워크 경사하강법(backpropagation, backward 계산) , 역전파 (0) | 2021.05.30 |
|---|---|
| 딥러닝 활성화함수(Relu , Maxpool2d) (0) | 2021.05.30 |
| 딥러닝의 인공 신경망(ANN,DNN,CNN)에 대하여 (1) | 2021.04.23 |
| 파이썬, 딥러닝 손실함수 교차엔트로피손실(CEE) 개념정리 (0) | 2021.04.21 |



